


The LLM RAG (Large Language Model Retrieve and Generate) pipeline stands out as a cutting-edge approach to enhancing the capabilities of language models. This methodology leverages the power of retrieval-augmented generation to combine the vast knowledge embedded in large language models with the precision and efficiency of database queries. The result is an AI system capable of producing more accurate, relevant, and contextually rich responses, bridging the gap between generative models and information retrieval systems.
In the rapidly evolving landscape of technology, where the demand for more efficient and scalable solutions is ever-present, Upstash emerges as a beacon for developers and businesses alike. This post delves deep into the essence of Upstash, exploring its advantages, and supported technologies, and providing a comprehensive guide on setting up and integrating Upstash with popular platforms. We will particularly focus on building a Retrieval Augmented Generation (RAG) pipeline, leveraging the capabilities of the Upstash Vector Database to enhance Large Language Models (LLMs).
Introduction to LLM RAG Pipeline
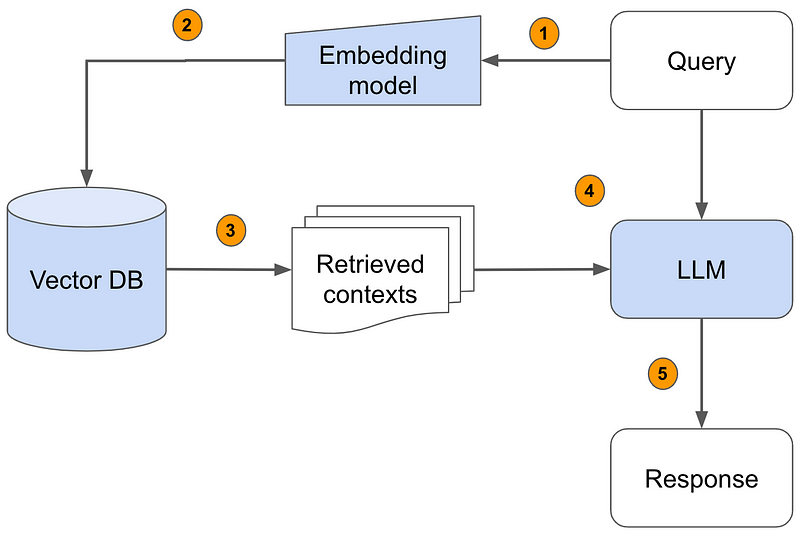
The fusion of Large Language Models (LLMs) with Retrieve and Generate (RAG) methodologies is redefining the boundaries of artificial intelligence in natural language processing. At its core, the LLM RAG pipeline is an innovative approach designed to augment the capabilities of language models by integrating them with information retrieval systems. This symbiotic relationship allows for the generation of responses that are not only contextually rich but also deeply rooted in factual accuracy.
The Concept of RAG
Retrieve and Generate operates on a simple yet powerful premise: before generating a response, the system first retrieves relevant information from a database or a corpus of documents. This process ensures that the generation phase is informed by the most pertinent and up-to-date information, allowing for responses that are both relevant and enriched with domain-specific knowledge. The RAG approach is particularly beneficial in scenarios where the language model alone might lack the necessary context or specific knowledge to produce an accurate response.
How LLMs Enhance RAG
Large Language Models, such as OpenAI’s GPT series, have been trained on diverse datasets comprising a vast swath of human knowledge. However, despite their extensive training, LLMs can sometimes generate responses that are generic or not fully aligned with the latest facts. Integrating LLMs with an RAG pipeline overcomes these limitations by providing a mechanism to supplement the model’s knowledge base with targeted, real-time data retrieval.
Example Use Case
Consider a scenario where a user queries an AI system about recent advancements in renewable energy technologies. A standalone LLM might generate a response based on its training data, which could be outdated. In contrast, an LLM RAG pipeline would first retrieve the latest articles, research papers, and reports on renewable energy before generating a response. This ensures that the information provided is not only contextually rich but also reflects the latest developments in the field.
The workflow of an LLM RAG pipeline involves several key steps:
Query Processing: The system parses the user’s query to understand the context and intent.
Data Retrieval: Based on the processed query, the system searches a database or corpus for relevant information. This step might involve complex vector searches to find the most pertinent documents or data points.
Content Generation: The retrieved information is then fed into the LLM, which generates a response incorporating this data, ensuring both relevance and accuracy.
Here’s a simplified example of how an LLM RAG pipeline works:
Install the required library:
pip install transformers
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
from datasets import load_dataset
# Initialize tokenizer and model
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="custom", passages_path="my_data/my_passages.json")
# Example query
query = "What are the latest advancements in renewable energy?"
# Encode the query and generate response
input_ids = tokenizer(query, return_tensors="pt").input_ids
outputs = model.generate(input_ids, num_beams=5, num_return_sequences=3, retrieval_vector=retriever.get_retrieval_vector(input_ids))
# Decode and print the response
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
We use the Hugging Face ‘transformers’ library to implement a basic RAG pipeline. This example illustrates the process of querying a model pre-trained on a specific dataset (in this case, “facebook/rag-token-nq”), but the principles can be extended to custom datasets and models tailored to specific domains or applications.
The integration of LLMs with RAG pipelines opens new horizons in AI-driven applications, making it possible to deliver responses that are not only linguistically coherent but also deeply informed by the latest data. As we continue to explore and refine these methodologies, the potential for creating more intelligent, responsive, and context-aware AI systems seems limitless.
Next, let’s delve into the Upstash Vector Database and explore how it complements the LLM RAG pipeline in data processing tasks.
Overview of Upstash Vector Database
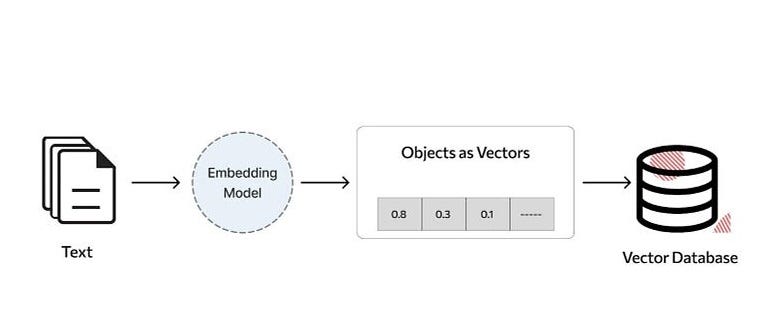
Overview of Upstash Vector Database
Upstash Vector Database is a powerful solution designed to enhance the performance and scalability of data applications, particularly those leveraging machine learning models like LLM RAG pipelines. At its core, Upstash provides a high-performance, cloud-native database that excels at storing and querying vectors — numeric representations of data points commonly used in machine learning and similarity search applications.
Unlike traditional databases that are optimized for storing structured data in tabular format, Upstash Vector Database is specifically engineered to handle high-dimensional vectors efficiently. This makes it an ideal choice for scenarios where you need to store and retrieve embeddings, embeddings of natural language text, images, or any other high-dimensional data.
One of the key features of Upstash Vector Database is its seamless integration with popular machine learning frameworks and libraries. Whether you’re using TensorFlow, PyTorch, or Hugging Face Transformers, Upstash provides native support and easy-to-use APIs for storing and querying vectors directly from your machine-learning pipelines.
Here’s a brief overview of how the Upstash Vector Database works:
Vector Storage: Upstash efficiently stores vectors in a distributed manner, ensuring fast and reliable access to your data. Vectors can be indexed and queried based on their similarity to other vectors, enabling sophisticated similarity search and recommendation systems. Upstash supports Cosine Similarity, Euclidean Distance, and Dot Product Similarity Search algorithms.
Scalability: Upstash is built on a scalable, cloud-native architecture that allows you to scale your vector database effortlessly as your data grows. Whether you’re handling thousands or millions of vectors, Upstash can accommodate your workload with minimal effort.
Performance: With its optimized indexing and query algorithms, Upstash delivers exceptional performance for vector retrieval and similarity search tasks. Whether you’re performing nearest neighbor search or clustering analysis, Upstash ensures low-latency responses even at scale.
Ease of Use: Upstash provides a simple and intuitive interface for managing your vector database. With its RESTful API and SDKs for popular programming languages, integrating Upstash into your application stack is straightforward and hassle-free.
In summary, the Upstash Vector Database is a game-changer for data applications that rely on high-dimensional vectors, such as machine learning models and similarity search systems. Its combination of performance, scalability, and ease of use makes it the perfect companion for building and optimizing LLM RAG pipelines and other data-driven applications.
Next, we’ll explore the step-by-step process of building an LLM RAG pipeline with Upstash Vector Database, from data preparation to optimization and fine-tuning.
Steps to Build an LLM RAG Pipeline with Upstash
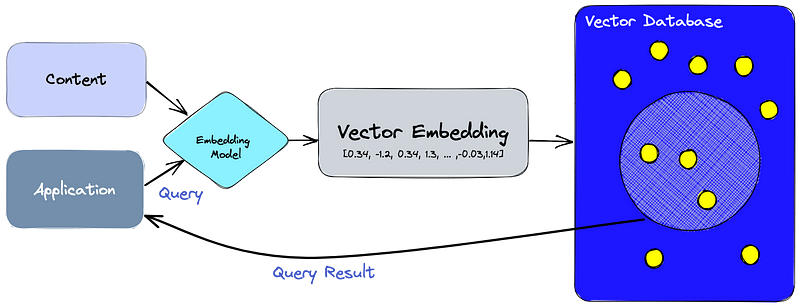
Steps to Build an LLM RAG Pipeline with Upstash
Building an LLM RAG pipeline with Upstash Vector Database involves several key steps, each crucial for achieving optimal performance and efficiency in data processing tasks. Let’s explore these steps in detail:
Data Preparation:
Data preparation is a critical step in building an LLM RAG pipeline with Upstash Vector Database. It involves transforming raw data into a format that is suitable for processing by language models and storing in Upstash.
Clean and Structured Data
Begin by ensuring that your data is clean and well-structured. This may involve removing duplicates, handling missing values, and standardizing formats. For text data, preprocessing steps such as tokenization, lemmatization, and removing stop words can improve the quality of input to the language model.
Install the required library:
pip install pandas
pip install nltk
import pandas as pd
# Load raw data
raw_data = pd.read_csv('raw_data.csv')
# Remove duplicates
clean_data = raw_data.drop_duplicates()
# Handle missing values
clean_data = clean_data.dropna()
# Tokenization and preprocessing (using nltk library)
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
stop_words = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()
def preprocess_text(text):
tokens = word_tokenize(text)
tokens = [token.lower() for token in tokens if token.isalpha()]
tokens = [lemmatizer.lemmatize(token) for token in tokens if token not in stop_words]
return ' '.join(tokens)
clean_data['processed_text'] = clean_data['text'].apply(preprocess_text)
Vector Representation:
Convert your data into vector representations suitable for storage in the Upstash Vector Database. Depending on the nature of your data, you may use techniques such as word embeddings, sentence embeddings, or image embeddings. These embeddings capture the semantic meaning of the data and allow for efficient storage and retrieval.
Example (using word embeddings with Word2Vec):
Install the required library:
pip install gensim
from gensim.models import Word2Vec
# Train Word2Vec model on preprocessed text data
word2vec_model = Word2Vec(sentences=clean_data['processed_text'], vector_size=100, window=5, min_count=1)
# Generate word embeddings for each token in the text
def generate_word_embeddings(text):
embeddings = []
for token in text.split():
if token in word2vec_model.wv:
embeddings.append(word2vec_model.wv[token])
return embeddings
clean_data['word_embeddings'] = clean_data['processed_text'].apply(generate_word_embeddings)
Storage in Upstash:
Store the vector representations of your data securely in the Upstash Vector Database. Upstash provides a simple and intuitive interface for storing and querying vectors, with support for various data types and formats. Use the Upstash RESTful API or SDKs to interact with the database and manage your data efficiently.
Initialize Upstash Client:
Begin by initializing the Upstash client with your API key. This key is required for authentication and access to your Upstash database.
pip install upstash-vector
from upstash_vector import Index
index = Index(url="UPSTASH_VECTOR_REST_URL", token="UPSTASH_VECTOR_REST_TOKEN")
Store Vectors:
Once you’ve initialized the client, you can start storing vectors in Upstash. Each vector is associated with a unique key, allowing for efficient retrieval later on.
from upstash_vector import Index
import random
index = Index(url="UPSTASH_VECTOR_REST_URL", token="UPSTASH_VECTOR_REST_TOKEN")
dimension = 128 # Adjust based on your index's dimension
vectors = [
Vector(
id="rag-1",
vector=[for i in range(clean_data['word_embeddings'])],
)
]
index.upsert(vectors=vectors)
Model Selection:
Choosing the right language model is crucial for building an effective LLM RAG pipeline. The selection process involves considering factors such as model architecture, size, computational resources, and the specific tasks your pipeline needs to perform. Here’s a detailed explanation, along with examples and code snippets, to guide you through the model selection process:
Identify Requirements:
Begin by identifying the requirements and constraints of your project. Consider factors such as the complexity of the tasks your pipeline needs to perform, the size of the dataset, and the computational resources available. For example, if you’re building a chatbot for simple conversational interactions, a smaller and more lightweight model may suffice. However, if you’re working on more complex natural language understanding tasks, you may need a larger and more powerful model.
Explore Pre-trained Models:
Explore the landscape of pre-trained language models available in the NLP community. There are various architectures to choose from, each with its strengths and weaknesses. Commonly used models include OpenAI’s GPT series (e.g., GPT-2, GPT-3), Google’s BERT, and Facebook’s RoBERTa. These models are trained on massive amounts of text data and can perform a wide range of NLP tasks with impressive accuracy.
Consider Fine-Tuning:
Depending on your specific use case and dataset, you may need to fine-tune a pre-trained model to adapt it to your task. Fine-tuning involves training the model on your dataset to improve its performance on a specific task or domain. This process requires labeled data and additional computational resources but can significantly enhance the model’s accuracy and relevance to your application.
Evaluate Performance:
Evaluate the performance of candidate models on your task or dataset using appropriate metrics and validation techniques. This may involve measuring metrics such as accuracy, precision, recall, and F1 score, depending on the nature of your task. Additionally, consider factors such as inference speed, memory usage, and model size when evaluating performance.
Select Model:
Based on your requirements, exploration of pre-trained models, fine-tuning efforts, and performance evaluation, select the model that best fits your needs. Choose a model that strikes the right balance between accuracy, computational resources, and scalability for your project.
Example (using Hugging Face’s Transformers library to load a pre-trained GPT-2 model):
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Load pre-trained GPT-2 model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
Integration with Upstash:
Integrating the Upstash Vector Database into your LLM RAG pipeline architecture is essential for efficient storage and retrieval of vectors. Upstash provides comprehensive documentation and easy-to-use APIs for seamless integration with popular machine-learning frameworks and libraries.
Initialize Upstash Client:
Begin by initializing the Upstash client with your API key. This key is required for authentication and access to your Upstash database.
Do follow the steps shown above for the initialization.
Store Vectors:
Once you’ve initialized the client, you can start storing vectors in Upstash. Each vector is associated with a unique key, allowing for efficient retrieval later on.
Do follow the steps shown above for the store vectors.
Retrieve Vectors:
Retrieve vectors from Upstash using their corresponding keys. This allows you to access the stored vectors for further processing in your LLM RAG pipeline.
result = index.fetch("rag-1")
# Display the fetched vectors
for vector_info in result.vectors:
print("ID:", vector_info.id)
print("Vector:", vector_info.vector)
print("Metadata:", vector_info.metadata)
Optimization and Fine-Tuning:
Optimizing and fine-tuning your LLM RAG pipeline is essential for achieving maximum efficiency and performance. By experimenting with different retrieval and generation strategies and continuously monitoring and adjusting your pipeline, you can enhance its responsiveness and accuracy. Here’s a detailed explanation, along with examples and code snippets, to guide you through the optimization and fine-tuning process:
from transformers import GPT2LMHeadModel, GPT2Tokenizer, Trainer, TrainingArguments
# Initialize model and tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# Define training arguments
training_args = TrainingArguments(
per_device_train_batch_size=4,
num_train_epochs=3,
learning_rate=5e-5,
logging_dir='./logs',
)
# Define trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
# Fine-tune model
trainer.train()
At its core, Upstash is a serverless data storage solution designed to meet the demands of modern, cloud-native applications. Unlike traditional databases that require dedicated server infrastructure, Upstash operates on a fully managed platform, eliminating the need for manual scaling, server maintenance, and complex configuration. This paradigm shift towards serverless computing brings forth numerous advantages, especially for developers and organizations aiming to streamline their operations and focus on innovation rather than infrastructure management.
Continuous Optimization:
Continuous optimization is a crucial aspect of maintaining peak performance and efficiency in LLM RAG pipelines. By iteratively refining pipeline parameters, adjusting strategies, and incorporating feedback, developers can ensure that their pipelines remain responsive and adaptive to changing conditions.
def optimize_pipeline():
# Define state space and action space
state_space = […] # Define state space based on pipeline parameters
action_space = […] # Define action space for adjusting parameters
# Initialize Q-table with random values
q_table = np.random.rand(len(state_space), len(action_space))
# Define exploration rate and discount factor
epsilon = 0.1
gamma = 0.9
# Run reinforcement learning algorithm
for episode in range(num_episodes):
state = initial_state
while not terminal_state:
# Choose action based on epsilon-greedy policy
if np.random.rand() < epsilon:
action = np.random.choice(action_space)
else:
action = np.argmax(q_table[state])
# Execute action and observe reward and next state
reward, next_state = execute_action(action)
# Update Q-value based on Bellman equation
q_table[state, action] += learning_rate * (reward + gamma * np.max(q_table[next_state]) - q_table[state, action])
state = next_state
return optimal_parameters
# Continuous optimization loop
while True:
optimize_pipeline()
Conclusion
Building an LLM RAG (Large Language Model Retrieval-Augmented Generation) pipeline with Upstash Vector Database offers a powerful solution for text generation tasks. Throughout this guide, we’ve explored the key steps involved in constructing such a pipeline, from data preparation to model selection, integration with Upstash, optimization, and continuous improvement through feedback loops.
By leveraging the Upstash Vector Database, developers can efficiently store and retrieve vector representations of data, enabling fast and scalable text generation. Integrating Upstash into the pipeline architecture provides benefits such as speed, scalability, reliability, efficiency, ease of use, and cost-effectiveness.
Furthermore, optimizing the pipeline parameters and continuously refining its performance through iterative improvements and user feedback ensures that it remains adaptive and responsive to evolving requirements.
In summary, by following the guidelines outlined in this guide and harnessing the capabilities of Upstash Vector Database, developers can build robust and efficient LLM RAG pipelines that deliver contextually relevant and high-quality text generation, enhancing user experiences and driving value for their applications.